Dans un monde numérique en constante évolution, la fiabilité des réseaux est cruciale. Imaginez un instant qu’un seul point de défaillance puisse paralyser toute une infrastructure. C’est là qu’intervient le Redundancy Protocol, un allié indispensable pour garantir des réseaux fiables et opérationnels en tout temps. En maîtrisant les protocoles de redondance, tels que le HSRP ou le VRRP, vous assurez une tolérance aux pannes et offrez une haute disponibilité à votre réseau. Notre guide complet vous accompagnera pour comprendre, configurer et optimiser ces protocoles essentiels, tout en évitant les erreurs courantes. L’objectif ? Vous fournir toutes les clés pour maintenir une sécure continuité des opérations, même face aux imprévus.
Qu’est-ce que le Redundancy Protocol ?
Définition et Objectifs
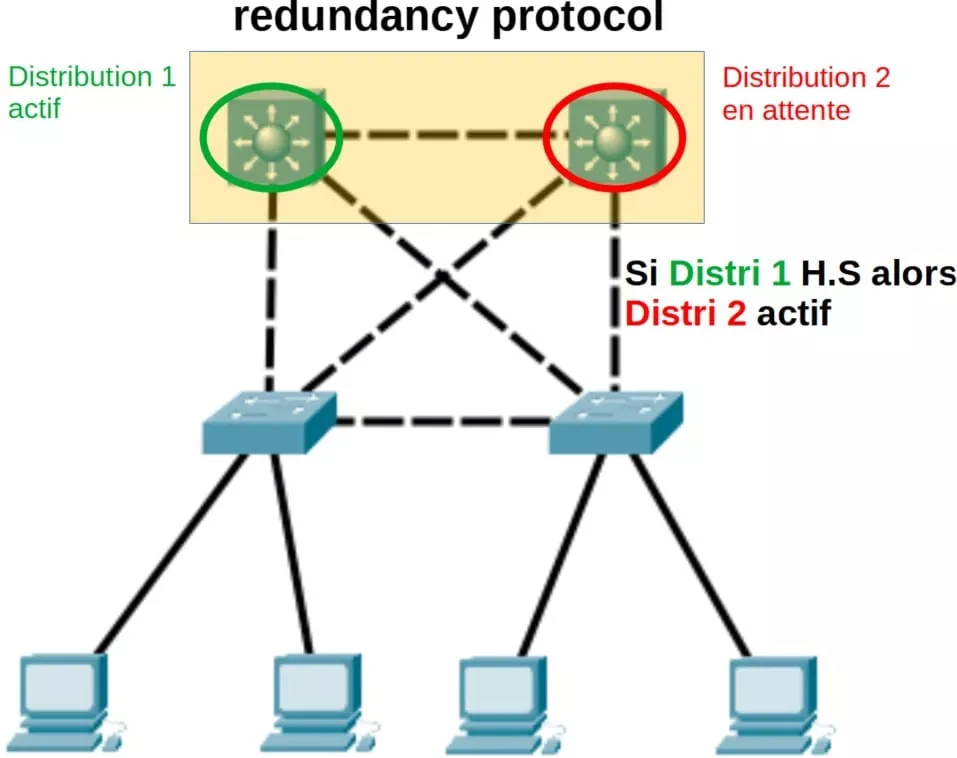
Le Redundancy Protocol, ou protocole de redondance, est essentiel pour minimiser les interruptions de service dans un réseau. Il s’agit de mécanismes qui permettent de désigner automatiquement un routeur de secours pour remplacer un routeur principal en cas de défaillance. L’objectif est d’assurer la continuité du service et de maintenir une connexion réseau stable et fiable.
Pourquoi est-il essentiel pour les réseaux ?
Imaginez un réseau sans mécanisme de redondance : une seule panne de routeur pourrait entraîner l’interruption totale de services critiques tels que le courrier électronique, la visioconférence ou même l’accès à l’internet. L’implémentation de protocoles de redondance garantit une tolérance aux pannes, assurant ainsi que le trafic peut s’acheminer par une autre route disponible en cas de problème. Par conséquent, la haute disponibilité des réseaux devient une réalité tangible.
Les Protocoles de Redondance les Plus Courants
Quel est le rôle du HSRP (Hot Standby Router Protocol) ?
Le HSRP, développé par Cisco, est utilisé pour fournir une continuité de la passerelle par défaut en cas de panne de réseau dans un réseau routé. Il fonctionne en permettant à plusieurs routeurs de gérer ensemble une seule adresse IP virtuelle. En cas de panne du routeur actif, le routeur de secours prend automatiquement la relève, assurant ainsi la continuité du service.
Par exemple, dans un réseau d’entreprise avec deux routeurs configurés en HSRP, si le routeur principal, dit « actif », tombe en panne, le routeur « de secours » deviendra actif sans intervention humaine. Ce basculement est transparent pour les utilisateurs.
En quoi consiste le VRRP (Virtual Router Redundancy Protocol) ?
Le VRRP est un protocole standardisé qui fournit une capacité similaire à celle du HSRP. Il permet également de protéger la continuité de la passerelle par défaut en cas de défaillance du routeur. Le principal avantage du VRRP réside dans sa compatibilité multi-fournisseurs, ce qui en fait un choix populaire pour les réseaux utilisant divers équipements.
Le GLBP (Gateway Load Balancing Protocol) : Pourquoi l’utiliser ?
Le GLBP, également développé par Cisco, combine la tolérance aux pannes avec l’équilibrage de charge. Contrairement au HSRP ou VRRP, qui affectent un seul routeur comme actif, le GLBP distribue le trafic à plusieurs routeurs en fonction de la charge. Cela améliore non seulement l’efficacité mais réduit également la congestion dans le réseau.
Imaginons que vous gériez un centre de données où le trafic est souvent fluctuant. Avec GLBP, plusieurs routeurs peuvent gérer efficacement le trafic, équilibrant les charges et évitant les goulets d’étranglement.
Comment Fonctionne un Protocole de Redondance ?
Étapes et Mécanismes de Base
Les protocoles de redondance fonctionnent en surveillant l’état des routeurs et en effectuant un basculement automatique si le routeur actif devient indisponible. Typiquement, cela implique la configuration d’une adresse IP virtuelle partagée par les routeurs du groupe. Le protocole assure une communication continue entre les membres du groupe pour déterminer leur statut.
Comment intervient-il en cas de panne ?
Lorsqu’un routeur principal tombe en panne, le protocole de redondance effectue une élection parmi les routeurs restants pour désigner le prochain routeur actif. Ce processus de basculement est transparent pour les utilisateurs finaux, qui ne subiront aucune interruption visible.
Par exemple, dans un environnement de bureau utilisant HSRP, si le routeur principal échoue, le protocole désigne rapidement un routeur de secours pour prendre la relève, maintenant ainsi les services réseau en fonctionnement sans nécessiter de configuration manuelle.
Avantages et Limitations des Protocoles de Redondance
Quels bénéfices attendre de leur utilisation ?
L’utilisation de protocoles de redondance offre plusieurs avantages, notamment une disponibilité continue des services, une amélioration de la fiabilité et une gestion efficace des ressources de réseau. En cas de panne, la transition vers le routeur de secours est immédiate et sans intervention humaine.
Quelles sont les restrictions possibles ?
Malgré leurs nombreux avantages, ces protocoles ne sont pas exempts de limitations. Ils nécessitent une infrastructure redondante, ce qui peut augmenter les coûts. De plus, leur mise en œuvre peut être complexe, surtout dans des environnements multi-fournisseurs où l’interopérabilité peut poser des défis.
Configuration d’un Protocole de Redondance
Étapes de Configuration Basique
Pour configurer un protocole de redondance comme le HSRP, il est souvent nécessaire de définir des adresses IP virtuelles et de configurer les timers pour assurer la fluidité du basculement. L’interface ligne de commande (CLI) des routeurs est généralement utilisée pour cette configuration.
interface GigabitEthernet0/0
standby 1 ip 192.168.1.1
standby 1 priority 120
standby 1 preemptErreur à éviter lors de la configuration
Les erreurs courantes incluent une mauvaise synchronisation des timers entre les routeurs ou une configuration erronée des priorités. Une mauvaise configuration peut entraîner des basculements intempestifs ou l’absence de redondance réelle.
Cas d’Utilisation et Scénarios Pratiques
Exemple de Mise en Œuvre dans un Réseau d’Entreprise
Dans une entreprise utilisant HSRP, plusieurs routeurs peuvent être configurés pour partager une adresse IP virtuelle. Cela assure qu’en cas de panne du routeur principal, le trafic réseau est immédiatement redirigé via le routeur de secours, garantissant ainsi une disponibilité continue.
Comparaison de Scénarios avec et sans Redondance
Dans un environnement sans redondance, la défaillance d’un appareil central peut entraîner des pertes de connexion importantes. En revanche, un réseau redondant réduit considérablement ce risque en assurant un basculement immédiat, maintenant ainsi les services critiques en ligne.
Futur et Évolutions des Protocoles de Redondance
Quels développements technologiques attendre ?
À l’avenir, les protocoles de redondance sont susceptibles de davantage intégrer des solutions basées sur le cloud pour optimiser l’acheminement du trafic et améliorer la tolérance aux pannes. L’essor de l’intelligence artificielle pourrait aussi automatiser et affiner les processus de basculement, rendant les réseaux encore plus robustes et autonomes.
Conclusion : Garantir des Réseaux Fiables grâce aux Protocoles de Redondance
En conclusion, les Redundancy Protocols jouent un rôle crucial pour assurer des réseaux fiables et tolérants aux pannes. Grâce à des mécanismes comme le HSRP, le VRRP et le GLBP, il est possible d’instituer une redondance réseau efficace, garantissant ainsi une haute disponibilité des services même en cas de défaillance. Bien que ces solutions nécessitent une infrastructure adéquate et une configuration soigneuse, elles représentent un investissement essentiel pour la continuité des opérations dans des environnements réseau exigeants. De futures évolutions, telles que l’intégration de technologies cloud et l’automatisation par intelligence artificielle, continueront de renforcer cette fiabilité, ouvrant la voie à des infrastructures encore plus robustes et efficaces.